スパイキングニューラルネットワークがエネルギー効率的な動きを発見
- 脚ロボットの省エネ歩行学習に寄与 -
2021/12/23
発表のポイント
概要
脚ロボット注3は高い移動性能を有することから様々な環境下での利用が期待されますが、他の移動ロボット(車輪型など)と比較して移動のエネルギー効率が悪いことが課題とされています。東北大学大学院工学研究科の林部充宏教授と納谷克海大学院生らの研究グループは、スパイキングニューラルネットワークを用いた深層強化学習によって、エネルギー効率のよい脚ロボットの歩行パターンの生成に成功しました。これまで、深層強化学習によってエネルギー効率のよい行動を学習するためには、エネルギーに関するペナルティ項を報酬注4に設ける手法が用いられてきました。しかし今回、スパイキングニューラルネットワークを用いることで、より厳しいペナルティ項においても歩行学習に成功し、エネルギー効率のよい歩行が学習できました。スパイキングニューラルネットワークについては、これまでは主にノイズに対する耐性や環境適応性が可能という点が注目されてきましたが、スパイキングニューラルネットワークの導入により、運動学習分野での新たな用途への活用が期待されます。
本成果は、2021年12月1日付で科学ジャーナルの「IEEE Access」に最終稿が掲載されました(投稿版は11月9日公表済)。
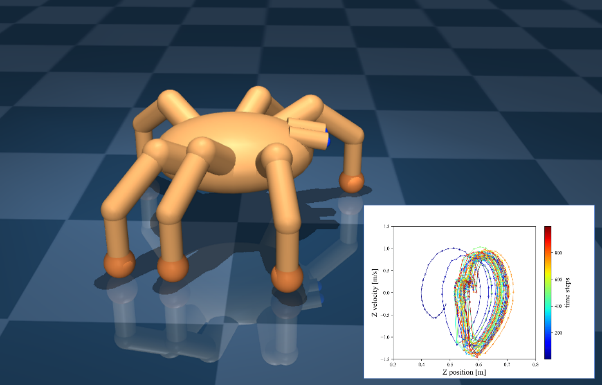
スパイキングニューラルネットワークによって歩行を学習した脚ロボットモデル
関連動画
Spiking Neural Network Discovers Energy-Efficient Hexapod Motion in Deep Reinforcement Learning
研究の背景
脚ロボットは他の移動ロボットと比較し、高い移動能力と安定性を有していることから厳しい環境下での利用が期待され、研究開発が盛んに行われています。様々な制御手法が提案されていますが、なかでも深層強化学習を用いることで、何も外部情報がない状態から、環境との相互作用を繰り返すことにより、最適な行動を学習することが期待されています。
一方で脚ロボットは搭載できるバッテリーが限られており、かつ長時間利用することが想定されるため消費エネルギーをできるだけ抑える必要があります。これまで深層強化学習による運動学習において動作のエネルギー効率を高めるための工夫として報酬項にエネルギーに関するペナルティ項を導入するという手法が知られていますが、最適な運動を得るためには報酬項の細かい調整が必要となり、計算コストも課題となります。そこで本研究ではスパイキングニューラルネットワークとよばれるニューラルネットワークに注目し、深層強化学習とスパイキングニューラルネットワークを組み合わせ、ペナルティ項の大きさを変えながら学習を行い、運動エネルギー効率の高い歩行が学習できるかを検証しました。
研究の内容
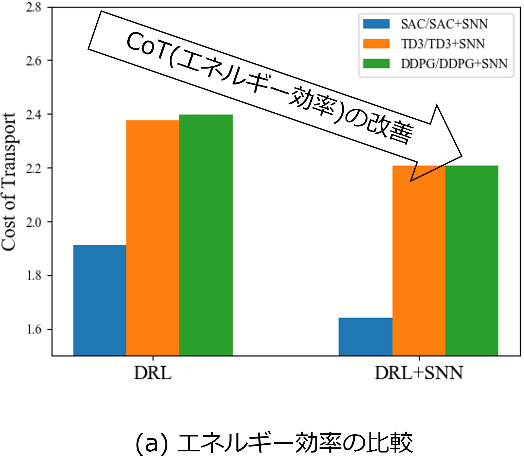
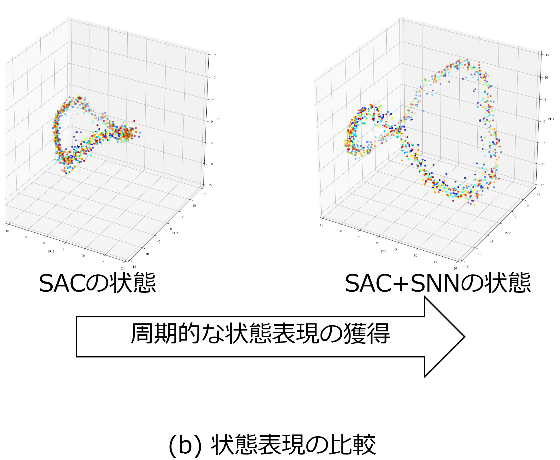
本研究では6脚型のロボットを使用し、通常の深層強化学習とスパイキングニューラルネットワークを用いた深層強化学習とで歩行を学習し、エネルギー効率の比較評価を行いました。図1のようにCost of Transport(移動コスト)がスパイキングニューラルネットワークの使用により低減することがわかりました。その後、スパイク形式にエンコードされたロボットの状態がどのように分離されているかPCA(主成分分析)を用いて比較を行いました。スパイキングニューラルネットワークを用いることで、各アルゴリズムについて、よりエネルギーのペナルティ項が大きい厳しい条件において学習が可能になりました。このことから、スパイキングニューラルネットワークを用いた深層強化学習による歩行は、通常の深層強化学習の方法で得た歩行と比較してエネルギー効率が良いということが導き出されます。また、スパイク形式にエンコードされたロボットの状態は、通常時の状態よりも周期的な構造に分離されていることがわかりました。スパイク形式に変換して学習を行うことで、歩行の周期性をより捉えることが可能になったと考えられます。これまでスパイキングニューラルネットワークはノイズに対する耐性や環境適応性、省電力な計算機実装が可能という利点のみに注目されていましたが、運動学習分野での新たな用途への活用が期待されます。
本研究は科学研究費補助金 (新学術領域) 超適応プロジェクト(B05-01)20H05458 の支援を受けて行ったものです。
研究の意義・今後の展望
スパイキングニューラルネットワークと深層強化学習の組み合わせによりエネルギー効率のよい運動パターンを生成することに成功しました。特に深層強化学習の手法であるSoft Actor-Criticはもともと探索能力の高いアルゴリズムとして知られていますが、スパイキングニューラルネットワークを組み合わせることでさらにエネルギー効率のよい運動生成が可能であるということがわかりました。これはスパイキングニューラルネットワークの新たな可能性を示唆する研究成果であり、更なる応用が期待されます。
用語解説
注1 スパイキングニューラルネットワーク
スパイクニューロンを構成素子とし、スパイク(ニューロンの発火)によって情報処理を行うニューラルネットワーク。膜電位を内部状態として持ち、時系列を考慮した計算が可能である他、ニューロモルフィックデバイスを用いることで省電力な計算が可能である。
注2 深層強化学習
環境で試行錯誤を繰り返すことにより最適な行動を学習する枠組みのことを強化学習と呼び、それに深層学習を利用したものを深層強化学習と呼ぶ。
注3 脚ロボット
脚の接地点を踏換えて移動する形式の歩行ロボットで、車輪式のような連続接地を必要とせず、接地不可能な凹凸部分や軟弱部分をまたぎ移動できるという特徴を持つ。
注4 報酬
強化学習の枠組みで用いられる計算指針のようなもので、AIが導いた結果の評価として得られるものを報酬と呼び、その逆をペナルティ(罰則)と呼ぶ。
論文情報
著者: Katsumi Naya, Kyo Kutsuzawa, Dai Owaki, Mitsuhiro Hayashibe
掲載誌: IEEE Access, Nov 2021, 9, 150345 - 150354
DOI: 10.1109/ACCESS.2021.3126311
URL: https://ieeexplore.ieee.org/document/9606760
お問合せ先
東北大学大学院工学研究科 ロボティクス専攻 教授 林部 充宏
TEL:022-795-6970
E-mail:mitsuhiro.hayashibe.e6@tohoku.ac.jp
